
티스토리 뷰

안녕하세요, WoodyCode입니다. 🚀
서비스 규모가 커지고 인프라가 복잡해질수록 '평균(Average)' 지표는 위험한 함정이 됩니다. 99%의 사용자가 쾌적해도, 1%의 사용자가 겪는 10초 이상의 지연은 전체 서비스 신뢰도를 갉아먹기 때문입니다.
오늘은 개발자의 시각에서, 단순한 그래프를 넘어 장애 전조 현상을 시각적으로 포착하는 실시간 히트맵 구축 전략을 공유합니다.
1. 왜 모니터링이 필요한가?
서버가 수십 대를 넘고 멀티 클라우드가 일상이 된 지금, 모든 서버를 완벽히 신뢰하기란 불가능합니다. 특히 특정 리전 장애나 트래픽 폭주를 소수 인원이 수동으로 대응하는 것은 한계가 명확합니다.
결국 안정적인 운영을 위해서는 단순히 로그를 쌓는 수준을 넘어선 모니터링 체계가 필수입니다.
- 통합(Aggregation): 분산된 메트릭을 단일 진실 공급원(Single Source of Truth)으로 집결.
- 직관(Observability): 단순 로그를 넘어 데이터 흐름을 시각화하여 즉각적 의사결정 지원.
- 예측(Forecasting): 과거 추세 분석을 통한 리소스 증설 및 장애 예방(Capacity Planning).
2. 데이터 수집 DB 선택: 왜 Prometheus인가?
시계열 데이터 수집을 위해 InfluxDB와 비교 후 Prometheus를 채택했습니다.
| 비교 항목 | Prometheus (선택) | InfluxDB |
| 수집 방식 | Pull-based: 서버가 데이터를 직접 가져옴 | Push-based: 앱이 데이터를 던져줌 |
| 관심사 분리 | 명확함 (메인 서버 로직에 영향 미미) | 낮음 (앱에 모니터링 로직 추가 필요) |
| 라이선스 | 완전 오픈소스 (CNCF 프로젝트) | 유료/무료 버전 분리 |
| 확장성 | 클라우드 네이티브 환경에 최적화 | 분산 환경 구축 시 고비용 발생 |
3. 실시간 히트맵의 전략적 활용 시나리오
⚡ 신규 기능 배포 직후 (Canary 배포)
바뀐 UI에서 길을 잃고 특정 영역을 연타하는 'Rage Click(분노의 클릭)' 발생 여부를 실시간으로 확인합니다. 이를 통해 UX 설계 결함을 즉시 인지하여 대규모 장애 전 **롤백(Rollback)**을 결정할 수 있습니다.
📈 트래픽 폭주 시 병목 구간 파악
DB 쿼리 응답 시간 히트맵을 통해 시스템을 저하시키는 'Hot Spot' 쿼리를 찾아냅니다. 막연한 증설 대신 인덱싱이나 캐싱 처리를 통해 효율적으로 문제를 해결하는 근거가 됩니다.
4. 실습: Prometheus + Grafana 로컬 환경 구축 (macOS)
맥북에서 Docker를 통해 구축한 환경은 실제 Linux 서버 환경과 기술적으로 동일하게 작동합니다.
Step 1: 🛠️환경 설정
1) docker-compose 설정 파일 만들기
docker-compose를 이용하면 개별 툴을 일일이 설치할 필요 없이 환경을 구축할 수 있습니다. (단, Docker Desktop은 미리 설치되어 있어야 합니다.)
docker-compose.yml
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- prometheus
2) Prometheus 설정 파일 만들기
같은 폴더에 prometheus.yml 파일을 만들고 아래 내용을 넣으세요. 프로메테우스가 자기 자신을 모니터링하도록 하는 최소한의 설정입니다.
global:
scrape_interval: 15s # 15초마다 데이터 수집
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
3) .yml 설정 파일 실행하기
터미널에서 해당 폴더로 이동한 뒤 명령어를 입력합니다.
❗️ Docker 실행 오류:'악성코드' 경고 해결 방법
docker-compose up -d
2. 실행 상태 확인
# 컨테이너가 'Up' 상태인지 확인
docker-compose ps
3. 서비스 종료 시
# 컨테이너 정지 및 삭제 (리소스 반납)
docker-compose down
Step2: 📊Grafana에서 히트맵 대시보드 만들기
1) Grafana 접속 및 로그인
- 주소창에 http://localhost:3000을 입력합니다.
- 로그인 창이 뜨면 아래 정보를 입력하세요.
- ID: admin
- Password: admin (첫 로그인 후 비밀번호를 바꾸라는 창이 뜨면 Skip 하시거나 원하는 걸로 바꾸시면 됩니다.)

2) Prometheus를 데이터 소스로 연결
그라파나가 프로메테우스의 일기장을 읽을 수 있게 연결해줘야 합니다.
- 왼쪽 메뉴에서 Connections -> Data Sources를 클릭합니다.
- Add data source 버튼을 누르고 Prometheus를 선택합니다.
- Connection 항목의 Prometheus server URL에 다음을 입력하세요:
- http://prometheus:9090 (컨테이너끼리 통신하기 때문에 localhost 대신 이름을 씁니다.)

4. 화면 맨 아래로 내려가서 Save & Test를 누릅니다.
- Successfully queried the Prometheus API.라는 녹색 메시지가 뜨면 성공!
3) 실시간 히트맵 그리기
- 왼쪽 상단 메뉴(작은 사각형 4개 아이콘) -> Dashboards -> New -> Add Visualization 클릭.
- 데이터 소스로 방금 만든 Prometheus를 선택합니다.
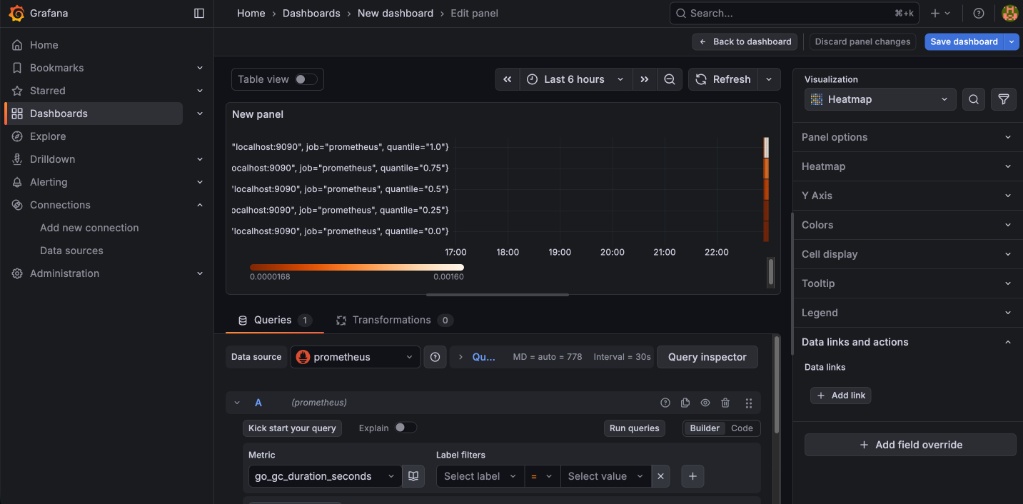
- 오른쪽 패널 설정창에서 Visualization을 클릭해 Time series에서 **Heatmap**으로 변경합니다.
- 가운데 쿼리 입력창(A)에 아래 코드를 복사해서 넣고 Shift + Enter를 누르세요.
- go_gc_duration_seconds (시스템 내부의 청소 시간을 실시간 히트맵으로 보여줍니다.)

Step3: 🔔 실전 알람(Alerting) 자동화
관리자가 부재중인 시간에도 대응하기 위해 Slack Webhook을 연동합니다.
1) 알람 보낼 채널 설정 (Contact Points)
먼저 어디로 알람을 받을지 정해야 합니다. (가장 많이 쓰는 Slack 기준)
- 그라파나 왼쪽 메뉴에서 Alerting -> Contact points 클릭.
- Add contact point 클릭.
- 이름을 Slack-Alert으로 정하고, 유형(Integration)에서 Slack 선택.
- 슬랙의 Webhook URL을 넣고 Test를 눌러 내 폰으로 메시지가 오는지 확인합니다.
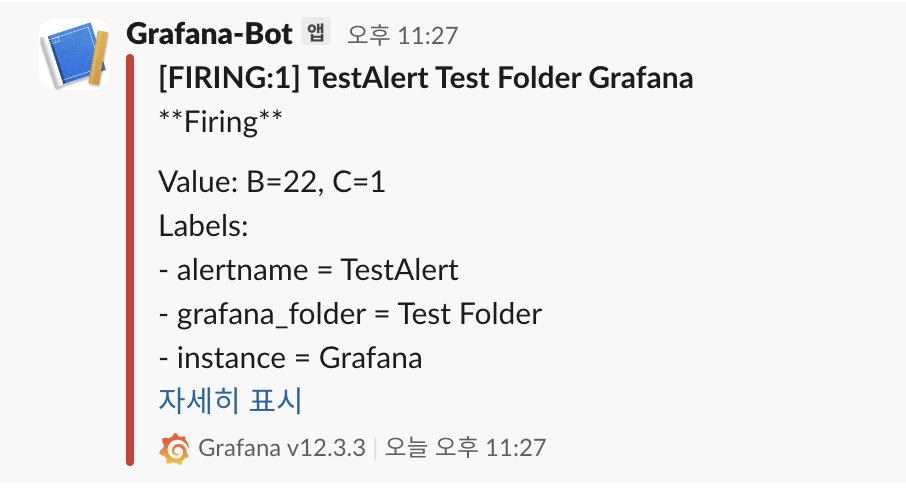
2) 알람 규칙 만들기 (Alert Rules)
이제 아까 만든 히트맵 지표가 특정 수치를 넘으면 알람이 울리게 설정합니다.
- 왼쪽 메뉴 Alerting -> Alert rules -> Create alert rule 클릭.
- 알람 이름을 정합니다. (예: System Latency High)
- Define query: 아까 히트맵에 썼던 쿼리를 넣습니다.
- 예: go_gc_duration_seconds{quantile="0.5"} (중간값 기준)
- Define condition: * IS ABOVE를 선택하고 수치를 입력합니다. (예: 0.01 - 시스템 청소 시간이 0.01초를 넘어가면 문제가 있다고 판단)
- Details: 이 알람이 떴을 때 슬랙에 보일 메시지를 적습니다.
- "시스템 응답 속도가 지연되고 있습니다. 실시간 히트맵을 확인하세요!"
'개발 👩💻 > DevOps🔥' 카테고리의 다른 글
| CrowdStrike 사태 1년 후 — 데이터 백업의 종말과 RTO·BCP 생존 전략 완벽 정리 (0) | 2026.03.11 |
|---|---|
| 맥북 Docker 실행 오류 해결법 — macOS Gatekeeper·Quarantine 완벽 이해 가이드 (0) | 2026.02.20 |
- Total
- Today
- Yesterday
- 개인정보보호
- nextjs
- Xchat
- IT실패사례
- Moltbook
- OpenAI
- 실패아카이브
- 미래기술
- IT트렌드
- 데이터주권
- RSC
- 2026IT트렌드
- vibecoding
- ChatGPT
- 알리바바AI
- 엔비디아
- AI코딩
- 챗GPT
- 몰트북
- 빅테크실패
- 일론머스크
- OpenClaw
- 프롬프트엔지니어링
- 빅데이터분석
- 바이브코딩
- AI에이전트
- 데이터교차검증
- llm
- 사이버보안
- 젠슨황
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |